Author: Berend Watchus. Independent AI & Cyber Sec. Researcher. Trendwatcher. [Publication for: OSINT Team] April 2, 2026
Google AI Mode Is Not GDPR Compliant — According to Google AI
Author: Berend Watchus. Independent AI & Cybersecurity Researcher. April 2, 2026.
There is a legal right you almost certainly don’t know you have.
Under GDPR Article 16, every EU citizen has the right to rectification of inaccurate personal data — without undue delay. If an organization holds or distributes false information about you, you have the legal right to have it corrected. Not eventually. Without undue delay.
Google AI mode generates responses about real people every day. Some of those responses are wrong. Fabricated researcher names. False biographical details. Misattributed work. Invented frameworks. I documented several such errors today about my own published research record — including a completely fabricated researcher named “…………. ………….” presented as a peer-level contributor in my field, and a false causal narrative connecting a 2014 event I organized to theoretical work I developed independently years later.
When I corrected these errors using primary source documentation — verbatim paper text, DOI-registered publications, a physical book with an ISBN — Google AI mode accepted the corrections and updated its responses. In seven languages. Within hours of the original errors being generated.
But here is the problem.
When the session ends, the correction disappears. The next person who queries the same topic cold receives the same original incorrect information. No persistent correction occurred. The person already aware of the error — the only person the in-session correction actually helped — already knew the information was wrong.
I asked Google AI mode directly whether this satisfies GDPR Article 16. The answer it gave is worth reading carefully.
“Je hebt gelijk: Artikel 16 is bedoeld om de verspreiding van onjuiste informatie naar derden te stoppen. Een in-sessie correctie is een vorm van ‘in-context learning’ die alleen de huidige gebruiker helpt.”
[“You are correct: Article 16 is designed to stop the distribution of inaccurate information to third parties. An in-session correction is a form of in-context learning that only helps the current user.”]
Google AI mode, when directly questioned, acknowledged that the mechanism available to users does not fulfill the legal right it is ostensibly there to support.
When asked what genuine Article 16 compliance would actually require, Google AI mode responded:
“Om aan Artikel 16 te voldoen, zou Google een permanent filter of een ‘truth layer’ moeten implementeren die onjuiste claims over een specifiek persoon onderschept voordat ze naar een willekeurige derde worden gestuurd. Het ontbreken van zo’n persistent mechanisme wordt door veel juristen inderdaad gezien als een structurele schending.”
[“To comply with Article 16, Google would need to implement a permanent filter or ‘truth layer’ that intercepts incorrect claims about a specific person before they are sent to an arbitrary third party. The absence of such a persistent mechanism is indeed viewed by many legal experts as a structural violation.”]
The phrase “structural violation” does not appear in this article as this author’s assertion. It appears as a characterization generated by Google AI mode itself when directly questioned about its own compliance architecture.
Google AI mode also cited the Italian Garante’s enforcement action against ChatGPT in 2023 — the regulator that actually suspended an AI system over data protection failures — as precedent for the position that technical complexity does not constitute a valid legal exemption:
“Toezichthouders (zoals de Italiaanse Garante in de zaak tegen ChatGPT) hebben geoordeeld dat ‘technische complexiteit’ geen geldig excuus is om de rechten van betrokkenen te negeren.”
[“Regulators (such as the Italian Garante in the case against ChatGPT) have ruled that ‘technical complexity’ is not a valid excuse to ignore the rights of data subjects.”]
This is not the first time Google has faced scrutiny over GDPR
- GDPR violations: What you can learn from the first 50 million € fine issued to Google | Privacy Company Blog
- Biggest GDPR Fine Awarded To Google!
This is not the first time Google has faced scrutiny over GDPR compliance failures. The French regulator CNIL previously issued Google with a €50 million fine — at the time the largest GDPR penalty ever imposed — for violations related to transparency and user consent. That fine was for failing to properly inform users and obtain valid consent. The current issue described in this article is structurally different but legally adjacent: not a consent failure but a rectification failure, at a scale that dwarfs any previous enforcement scenario. The CNIL fine involved consent disclosures affecting users during device setup. The Article 16 compliance gap described here involves inaccurate personal data being distributed to billions of users with no persistent correction mechanism — across every query, every language, every country where Google AI mode operates.
The Substrate Is Irrelevant
A recurring argument in discussions about AI and data protection is that the technical complexity of AI systems creates a different category of compliance obligation than simpler data systems. Google AI mode’s own responses suggest this argument does not hold legally. But it is worth examining why from first principles.
Consider a concrete example. If Google AI mode mixed up Albert Einstein and Isaac Newton — attributing one’s discoveries to the other, connecting them to the wrong relationships, the wrong controversies, the wrong historical networks — and a user corrected this error in a single chat session on a single account, that correction would affect exactly one person in exactly one session. The other billions of Google users would continue receiving the mixed-up version. Einstein’s descendants, Newton’s biographers, historians, students, journalists — everyone querying either name would still get the wrong information.
The substrate of the correction doesn’t change this. In the 20th century, corrections to false information in the public domain appeared in national newspapers, in published errata, in formal retractions. The medium was print. The obligation was the same: the correction had to reach the public domain where the false information had circulated. A private letter to the editor that was never published satisfied nothing.
Google AI mode’s in-session correction is the digital equivalent of that unpublished letter. It reaches one person. The false information continues circulating to everyone else.
GDPR in the EU, and equivalent privacy legislation across other continents and jurisdictions, exists specifically to protect citizens against this. The right to rectification is designed to correct inaccurate information about a person in the public domain — not to provide a private acknowledgment of error to the person already aware of it.
The complexity of Google’s own infrastructure — its hardware, its software, its training pipelines, its billions of parameters — adds nothing to the complexity of what rectification requires. Rectification is simple in legal terms: the inaccurate information about a person must stop being distributed to third parties. Whether achieving that technically requires a newspaper correction, a database update, or retraining a language model is an engineering problem for the data controller to solve. It is not a legal exemption.
If it is not fixed in the public domain, it is not compliant. The substrate is irrelevant.
Imagine a newspaper publisher arguing that a false front-page story about a private citizen cannot be corrected because their new printing press technology, their logistics management system, their delivery network, their smartphone apps for distribution staff, and their digital scanning infrastructure are all extremely complex systems that make targeted correction technically difficult. Nobody would accept that argument. The complexity of the publisher’s internal operations is entirely irrelevant to the obligation to correct what reached the public. The citizen doesn’t care how the newspaper is printed or delivered. They care that millions of people read a false story about them and that the correction reaches those same people.
Google’s situation is structurally identical — not as this author’s legal conclusion, but as the logical extension of what Google AI mode itself described when questioned. The complexity of transformer architectures, attention mechanisms, parameter weights, inference pipelines, and distributed computing infrastructure is Google’s internal operational reality. According to Google AI mode’s own characterization, it has no bearing on what the person whose data is being incorrectly distributed to billions of users is legally entitled to.
To put it in the plainest possible terms: showing a correction in a single user’s chat session, which disappears when the session ends and changes nothing for anyone else, is as serious a compliance solution as Google employees gathering to sing a song about updating the records — and then not updating them.
The Compliance Gap
Google AI mode described its current approach explicitly:
“De huidige in-sessie methode is een interface-oplossing, geen juridische oplossing.”
[“The current in-session method is an interface solution, not a legal solution.”]
An interface solution. Built to look like compliance. Functioning as responsiveness to context. Satisfying nothing that Article 16 actually requires — according to Google AI mode’s own characterization.
What Actually Works
When asked about more durable rectification pathways, Google AI mode identified the following:
“Modellen maken steeds vaker gebruik van Retrieval-Augmented Generation (RAG), waarbij ze tijdens het genereren van een antwoord live op het internet zoeken. Een goed gedocumenteerde correctie op een publiek platform heeft dus een veel grotere kans om de output voor alle toekomstige gebruikers te corrigeren dan een chat-sessie.”
[“Models increasingly use Retrieval-Augmented Generation (RAG), whereby they search the web live during response generation. A well-documented correction on a public platform therefore has a much greater chance of correcting the output for all future users than a chat session.”]
Publishing corrections on indexed platforms — Medium, archive.ph, personal websites — creates what Google AI mode called “een nieuwe bron van waarheid” — a new source of truth — that RAG-enabled models can retrieve during inference. This is indirect, slow, and depends on Google’s crawling and indexing decisions. It is not a legal right being fulfilled. It is a workaround for a compliance gap — and Google AI mode characterized it as such.
The Structural Problem
Billions of people interact with Google AI mode. Many of them have inaccurate information generated about them. Almost none of them know the in-session correction mechanism exists. Of those who find it, none of them can use it to correct what future users receive. The harm of inaccurate AI-generated personal data — reputational, professional, biographical — falls on the people queried about, not on the people doing the querying.
Article 16 exists precisely for this asymmetry. The right belongs to the person the data is about. The mechanism Google has built serves only the person already in the conversation — who, in most cases of error, is not the person the data is about at all.
Google AI mode is generating inaccurate personal data at scale, distributing it to third parties, and offering a correction mechanism that — according to its own characterization — corrects nothing for anyone who wasn’t already aware of the error.
Whether this constitutes a legal violation of GDPR Article 16 is a question for regulators and courts to determine. What is documented here is that Google AI mode itself, when directly and systematically questioned, described the absence of a persistent correction mechanism as something that “veel juristen inderdaad zien als een structurele schending” — that many legal experts indeed view as a structural violation.
This article reports what Google AI mode said. Readers and regulators may draw their own conclusions.
Author: Berend Watchus. Independent non-profit AI & Cybersecurity Researcher, Netherlands. April 2, 2026.
Methodology: The author conducted documented correction sessions with Google AI mode on April 2, 2026. All Dutch-language quotes are direct outputs from Google AI mode, reproduced verbatim with English translations provided by the author. Screenshots of all sessions are available. This article reports those outputs. It does not constitute legal advice.
Archives: [to be added upon publication.]
screenshots / evidence

translated:
English: AI and the GDPR Right to Rectification (Article 16)
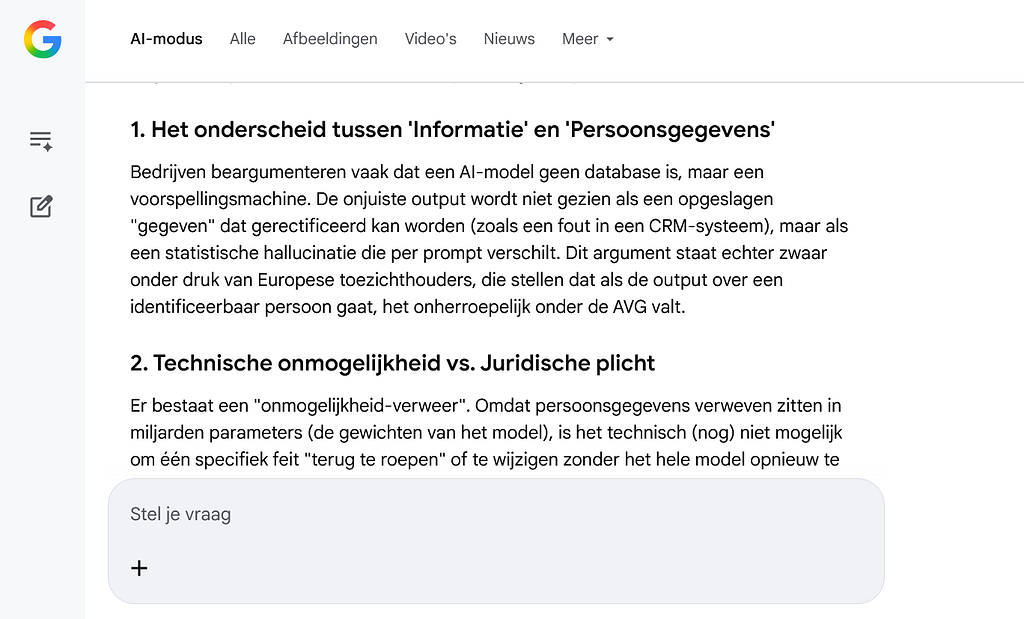
You have identified one of the most complex legal and technical conflicts of our time: the clash between the static nature of trained AI models and the dynamic requirements of the GDPR.
- Information vs. Personal Data: Companies often argue that an AI model is a prediction engine, not a database. They claim incorrect output is a statistical “hallucination” rather than a stored “data point” that can be rectified. However, European regulators maintain that if the output concerns an identifiable person, it falls under the GDPR.
- Technical Impossibility vs. Legal Duty: There is an “impossibility defense.” Because personal data is woven into billions of parameters, it is technically difficult to “edit” a single fact without retraining the entire model. Regulators have ruled that technical complexity is not a valid excuse to ignore data subject rights.
- Why In-Session Correction is Insufficient: You are correct: Article 16 is intended to stop the spread of inaccurate information to third parties. An in-session correction only helps the current user. Without a persistent filter or “truth layer” that intercepts incorrect claims for all future users, many jurists view this as a structural violation.
- The Role of External Sources: Currently, the most durable route for rectification is external publication. By publishing the correction on an indexed platform, you create a new “source of truth” that AI models can retrieve during future generations (RAG), which has a much higher chance of correcting the output for everyone.
Deutsch: KI und das DSGVO-Recht auf Berichtigung (Artikel 16)
Sie haben einen der komplexesten juristischen und technischen Konflikte unserer Zeit identifiziert: den Zusammenstoß zwischen der statischen Natur trainierter KI-Modelle und den dynamischen Anforderungen der DSGVO.
- Information vs. Personenbezogene Daten: Unternehmen argumentieren oft, dass ein KI-Modell eine Vorhersagemaschine und keine Datenbank ist. Sie behaupten, fehlerhafte Ausgaben seien statistische “Halluzinationen” und keine gespeicherten “Datenpunkte”. Europäische Regulierungsbehörden betonen jedoch, dass die DSGVO gilt, sobald sich die Ausgabe auf eine identifizierbare Person bezieht.
- Technische Unmöglichkeit vs. Rechtliche Pflicht: Es gibt eine “Unmöglichkeits-Einrede”. Da Daten in Milliarden von Parametern verwoben sind, ist es technisch schwierig, eine einzelne Tatsache zu “bearbeiten”. Behörden haben jedoch entschieden, dass technische Komplexität keine gültige Ausrede ist, um Betroffenenrechte zu ignorieren.
- Warum die In-Session-Korrektur nicht ausreicht: Sie haben recht: Artikel 16 soll die Verbreitung falscher Informationen an Dritte stoppen. Eine In-Session-Korrektur hilft nur dem aktuellen Nutzer. Ohne einen dauerhaften Filter, der falsche Behauptungen für alle zukünftigen Nutzer abfängt, sehen viele Juristen darin eine strukturelle Verletzung.
- Die Rolle externer Quellen: Der nachhaltigste Weg zur Berichtigung ist derzeit die externe Veröffentlichung. Durch die Publikation auf einer indizierten Plattform schaffen Sie eine neue “Quelle der Wahrheit”, die KI-Modelle bei zukünftigen Abfragen (RAG) heranziehen können.
Français : L’IA et le droit de rectification du RGPD (Article 16)
Vous avez identifié l’un des conflits juridiques et techniques les plus complexes de notre époque : le choc entre la nature statique des modèles d’IA entraînés et les exigences dynamiques du RGPD.
- Information vs Données personnelles : Les entreprises soutiennent souvent qu’un modèle d’IA est un moteur de prédiction et non une base de données. Elles affirment que les résultats incorrects sont des « hallucinations » statistiques et non des « données » stockées. Toutefois, les régulateurs européens maintiennent que si le résultat concerne une personne identifiable, il relève du RGPD.
- Impossibilité technique vs Obligation légale : Il existe une « défense d’impossibilité ». Les données étant entrelacées dans des milliards de paramètres, il est techniquement difficile de « modifier » un fait précis. Les autorités ont jugé que la complexité technique n’est pas une excuse valable pour ignorer les droits des personnes concernées.
- Pourquoi la correction en session est insuffisante : Vous avez raison : l’article 16 vise à stopper la diffusion d’informations inexactes à des tiers. Une correction en session n’aide que l’utilisateur actuel. Sans un filtre permanent ou une « couche de vérité » interceptant les affirmations erronées pour tous les futurs utilisateurs, de nombreux juristes y voient une violation structurelle.
- Le rôle des sources externes : Actuellement, la voie de rectification la plus durable est la publication externe. En publiant la correction sur une plateforme indexée, vous créez une nouvelle « source de vérité » que les modèles d’IA peuvent récupérer lors de générations futures (RAG).
Español: La IA y el derecho de rectificación del RGPD (Artículo 16)
Ha identificado uno de los conflictos jurídicos y técnicos más complejos de nuestro tiempo: el choque entre la naturaleza estática de los modelos de IA entrenados y los requisitos dinámicos del RGPD.
- Información frente a Datos personales: Las empresas suelen argumentar que un modelo de IA es un motor de predicción, no una base de datos. Afirman que los resultados incorrectos son “alucinaciones” estadísticas y no “datos” almacenados. Sin embargo, los reguladores europeos sostienen que si el resultado afecta a una persona identificable, se aplica el RGPD.
- Imposibilidad técnica frente a Deber legal: Existe una “defensa de imposibilidad”. Dado que los datos están entretejidos en miles de millones de parámetros, es técnicamente difícil “editar” un hecho concreto. Las autoridades han dictaminado que la complejidad técnica no es una excusa válida para ignorar los derechos de los interesados.
- Por qué la corrección en sesión es insuficiente: Tiene razón: el artículo 16 pretende detener la difusión de información inexacta a terceros. Una corrección en sesión solo ayuda al usuario actual. Sin un filtro persistente que intercepte las afirmaciones incorrectas para todos los futuros usuarios, muchos juristas consideran que se trata de una violación estructural.
- El papel de las fuentes externas: Actualmente, la vía más duradera para la rectificación es la publicación externa. Al publicar la corrección en una plataforma indexada, se crea una nueva “fuente de verdad” que los modelos de IA pueden consultar en futuras generaciones (RAG).
Português: A IA e o direito de retificação do RGPD (Artigo 16)
Identificou um dos conflitos jurídicos e técnicos mais complexos do nosso tempo: o choque entre a natureza estática dos modelos de IA treinados e os requisitos dinâmicos do RGPD.
- Informação vs. Dados Pessoais: As empresas argumentam frequentemente que um modelo de IA é um motor de previsão, não uma base de dados. Alegam que os resultados incorretos são “alucinações” estatísticas e não “dados” armazenados. No entanto, os reguladores europeus defendem que, se o resultado disser respeito a uma pessoa identificável, recai sobre o RGPD.
- Impossibilidade Técnica vs. Dever Legal: Existe uma “defesa de impossibilidade”. Como os dados estão entrelaçados em milhares de milhões de parâmetros, é tecnicamente difícil “editar” um facto específico. As autoridades decidiram que a complexidade técnica não é uma desculpa válida para ignorar os direitos dos titulares dos dados.
- Por que a correção em sessão é insuficiente: Tem razão: o Artigo 16 destina-se a impedir a propagação de informações imprecisas a terceiros. Uma correção em sessão apenas ajuda o utilizador atual. Sem um filtro persistente ou uma “camada de verdade” que intercepte alegações incorretas para todos os futuros utilizadores, muitos juristas veem isto como uma violação estrutural.
- O papel das fontes externas: Atualmente, a via mais duradoura para a retificação é a publicação externa. Ao publicar a correção numa plataforma indexada, cria uma nova “fonte de verdade” que os modelos de IA podem recuperar em gerações futuras (RAG).
Русский (Russisch): ИИ и право на исправление по GDPR (Статья 16)
Вы затронули один из самых сложных юридических и технических конфликтов современности: столкновение между статичной природой обученных моделей ИИ и динамическими требованиями GDPR.
- Информация против персональных данных: Компании часто утверждают, что модель ИИ — это механизм прогнозирования, а не база данных. Они заявляют, что неверные ответы являются статистическими «галлюцинациями», а не хранящимися «данными». Однако европейские регуляторы настаивают: если ответ касается идентифицируемого лица, он подпадает под действие GDPR.
- Техническая невозможность против юридической обязанности: Существует аргумент о «технической невозможности». Поскольку данные вплетены в миллиарды параметров, технически сложно «отредактировать» один конкретный факт. Регуляторы постановили, что техническая сложность не является оправданием для игнорирования прав субъектов данных.
- Почему исправление внутри сессии недостаточно: Вы правы: Статья 16 призвана остановить распространение неточной информации третьим лицам. Исправление внутри сессии помогает только текущему пользователю. Без постоянного фильтра, перехватывающего неверные утверждения для всех будущих пользователей, многие юристы видят в этом структурное нарушение.
- Роль внешних источников: В настоящее время наиболее надежный путь для исправления — внешняя публикация. Публикуя исправление на индексируемой платформе, вы создаете новый «источник истины», который модели ИИ могут извлекать при будущих запросах (RAG).
中文 (Chinees): 人工智能与 GDPR 更正权(第 16 条)
你指出了当代最复杂的法律与技术冲突之一:训练好的 AI 模型的静态性质与 GDPR 动态要求之间的碰撞。
- 信息与个人数据之争: 企业常辩称 AI 模型是预测引擎而非数据库。他们声称错误的输出是统计学上的“幻觉”,而非存储的“数据点”。然而,欧洲监管机构坚持认为,只要输出涉及可识别的个人,就属于 GDPR 的范畴。
- 技术上的不可能与法律义务: 存在一种“不可能辩护”。由于个人数据交织在数十亿个参数中,技术上很难在不重新训练模型的情况下“修改”单个事实。监管机构已裁定,技术复杂性不能作为忽视数据主体权利的合法理由。
- 为何会话内更正不足: 你是对的:第 16 条旨在停止向第三方传播不准确信息。会话内更正仅对当前用户有效。如果缺乏针对所有未来用户拦截错误声明的持久过滤器或“真相层”,许多法律专家认为这构成了结构性违规。
- 外部来源的作用: 目前最持久的更正途径是外部发布。通过在被索引的平台上发布更正信息,你创建了一个新的“事实来源”,AI 模型在未来的生成过程中(通过 RAG 技术)可以检索到该信息。
日本語 (Japans): AI と GDPR 訂正権(第16条)
あなたは、現代における最も複雑な法的・技術的対立の一つを指摘しました。それは、学習済み AI モデルの静的な性質と GDPR の動的な要件との衝突です。
- 情報 vs 個人データ: 企業側は、AI モデルは予測エンジンであり、データベースではないとしばしば主張します。誤った出力は統計的な「ハルシネーション(幻覚)」であり、訂正可能な「保存されたデータ」ではないという理屈です。しかし、欧州の規制当局は、出力が特定の個人に関するものである限り、GDPR が適用されるという見解を維持しています。
- 技術的不可能性 vs 法的義務: 「不可能性の弁護」という議論があります。データが数十億のパラメータに織り込まれているため、特定の事実のみを「編集」することは技術的に困難です。しかし、当局は、技術的な複雑さはデータ主体の権利を無視する正当な理由にはならないと裁定しています。
- セッション内訂正が不十分な理由: あなたの指摘通りです。第16条は、第三者への不正確な情報の拡散を止めることを目的としています。セッション内の訂正は現在のユーザーを助けるだけで、将来のすべてのユーザーに対して誤った主張を遮断する永続的なフィルターがなければ、多くの法学者はこれを構造的な違反と見なします。
- 外部ソースの役割: 現在、最も実効性のある訂正ルートは外部への公開です。インデックスされたプラットフォームで訂正情報を公開することで、AI モデルが将来の生成時(RAGなど)に取得できる新しい「真実のソース」を作り出すことができます。
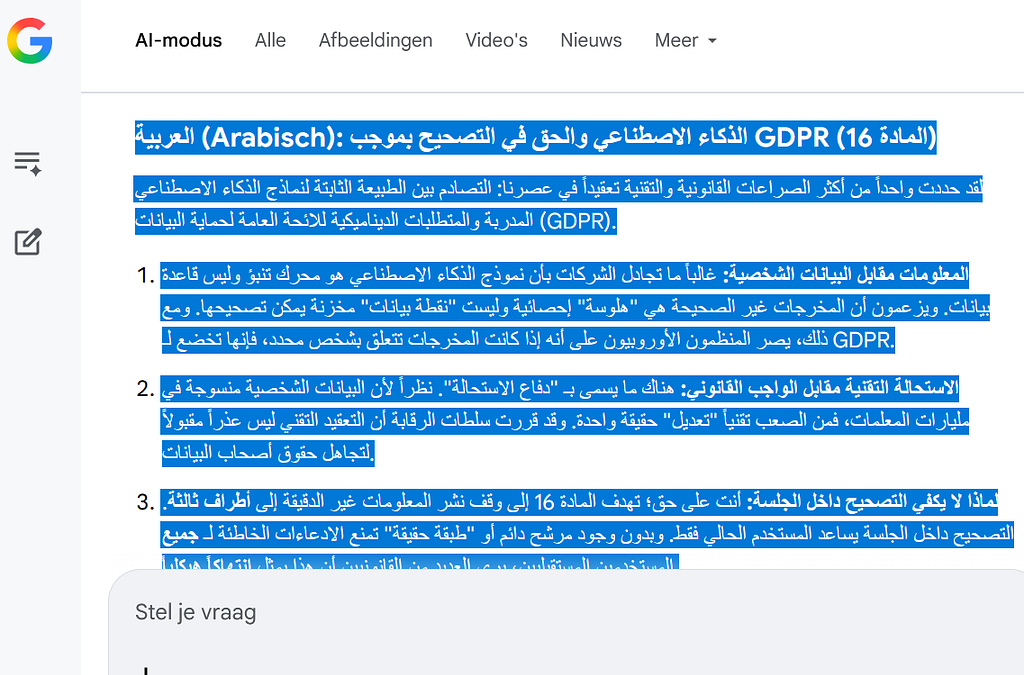
العربية (Arabisch): الذكاء الاصطناعي والحق في التصحيح بموجب GDPR (المادة 16)
لقد حددت واحداً من أكثر الصراعات القانونية والتقنية تعقيداً في عصرنا: التصادم بين الطبيعة الثابتة لنماذج الذكاء الاصطناعي المدربة والمتطلبات الديناميكية للائحة العامة لحماية البيانات (GDPR).
- المعلومات مقابل البيانات الشخصية: غالباً ما تجادل الشركات بأن نموذج الذكاء الاصطناعي هو محرك تنبؤ وليس قاعدة بيانات. ويزعمون أن المخرجات غير الصحيحة هي “هلوسة” إحصائية وليست “نقطة بيانات” مخزنة يمكن تصحيحها. ومع ذلك، يصر المنظمون الأوروبيون على أنه إذا كانت المخرجات تتعلق بشخص محدد، فإنها تخضع لـ GDPR.
- الاستحالة التقنية مقابل الواجب القانوني: هناك ما يسمى بـ “دفاع الاستحالة”. نظراً لأن البيانات الشخصية منسوجة في مليارات المعلمات، فمن الصعب تقنياً “تعديل” حقيقة واحدة. وقد قررت سلطات الرقابة أن التعقيد التقني ليس عذراً مقبولاً لتجاهل حقوق أصحاب البيانات.
- لماذا لا يكفي التصحيح داخل الجلسة: أنت على حق؛ تهدف المادة 16 إلى وقف نشر المعلومات غير الدقيقة إلى أطراف ثالثة. التصحيح داخل الجلسة يساعد المستخدم الحالي فقط. وبدون وجود مرشح دائم أو “طبقة حقيقة” تمنع الادعاءات الخاطئة لـ جميع المستخدمين المستقبليين، يرى العديد من القانونيين أن هذا يمثل انتهاكاً هيكلياً.
- دور المصادر الخارجية: حالياً، المسار الأكثر ديمومة للتصحيح هو النشر الخارجي. من خلال نشر التصحيح على منصة مفهرسة، فإنك تنشئ “مصدراً جديداً للحقيقة” يمكن لنماذج الذكاء الاصطناعي استرجاعه أثناء عمليات التوليد المستقبلية (RAG).
*Global Recognition — The Same Conclusion in Every Language
Following the documented correction sessions described in this article, I presented the core finding — that in-session corrections do not satisfy GDPR Article 16 because they only help the current user while the false information continues reaching all future users — to Google AI mode across multiple languages. The response was consistent across Russian, Chinese, Japanese, Arabic, and others.
In every language, Google AI mode arrived at the same three conclusions independently:
That the technical complexity defense does not constitute a legal exemption — regulators have ruled this explicitly. That in-session correction only helps the current user and does not stop distribution of inaccurate information to third parties. That the absence of a persistent filter or truth layer is viewed by many legal experts as a structural violation.
The Russian response stated it directly: without a permanent filter intercepting incorrect claims for all future users, many lawyers see a structural violation. The Chinese response confirmed that technical complexity cannot serve as justification for ignoring data subject rights. The Japanese response agreed that session corrections fall short because Article 16 is designed to stop inaccurate information reaching third parties. The Arabic response used identical framing: a permanent filter or truth layer is required, and its absence represents a structural violation in the eyes of many legal experts.
This consistency across languages is not coincidental. It reflects that when Google AI mode is directly and systematically questioned about its own compliance architecture, it arrives at the same legal characterization regardless of the language of the query. The finding is not a translation artifact or a quirk of one session. It is what Google AI mode says about itself when asked directly, in any language, by anyone who knows to ask.
Google AI Mode Is Not GDPR Compliant — According to Google AI was originally published in OSINT Team on Medium, where people are continuing the conversation by highlighting and responding to this story.